Originally published on Efficiently (Substack)
This is a continuation of a previous blog post about efficient data partitioning.
In the previous post, I discussed how data layout on disk impacts analytics performance. This post focuses on tactical implementation using open source technologies.
Topics I’ll cover:
- HDFS
- Blocks + Block Size
- Block sizes + tradeoffs
Background
Data organization on disk dramatically affects analytics performance. I previously explored row-oriented, columnar, and hybrid storage models — now let’s connect these concepts to modern data infrastructure.
Hadoop
Hadoop provides an ecosystem enabling:
- Distributed data storage (HDFS — Hadoop Distributed File System)
- Data querying (MapReduce)
- Compute resource management (YARN)
- Additional commons library and object store (Ozone)
This discussion focuses on HDFS as the most relevant storage-side component for understanding data partitioning.
HDFS
Let’s say you have an invaluable file that contains the names, addresses, and phone numbers of employees at your company.

That file lives on a single server. What happens if the server goes down?

Nobody can access the file. That’s a problem. So, you decide to store a copy of the file on two servers.

Great — now if one server goes down, the file is still available. But what happens when someone updates the file? You now have two copies that need to stay in sync.
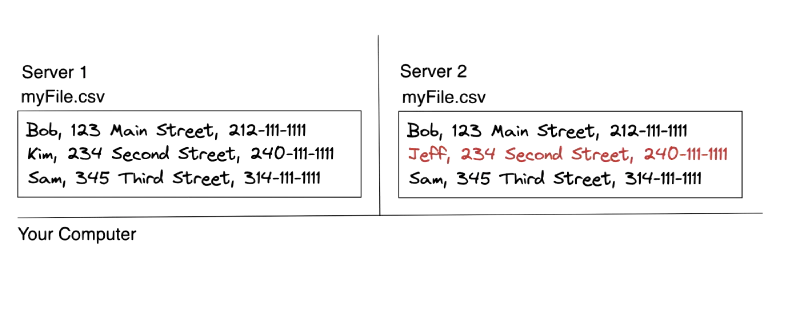
This orchestration complexity is the central problem that HDFS solves.
Blocks
HDFS stores data in blocks. These are the same Blocks from the last post. They are indivisible segments of data.
A block represents the minimum amount of data readable in a single operation — any read requires reading at least one complete block.
Files are divided into blocks during storage.

These blocks are then distributed across multiple cluster nodes.
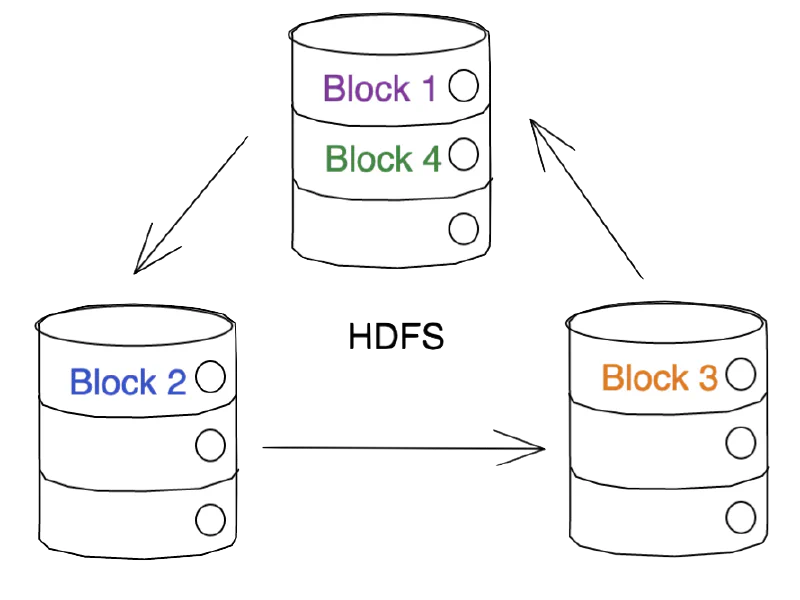
And then replicated for fault tolerance.
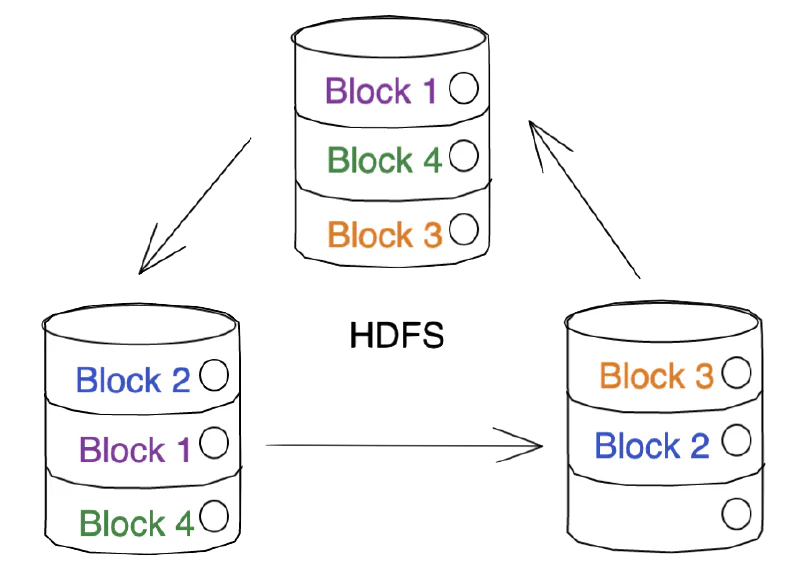
Architecture Note: These diagrams intentionally simplify HDFS architecture, omitting NameNode/DataNode separation, clients, and other components. The focus remains on partitioning concepts.
Block Size
The default Hadoop block size is 128MB (previously 64MB). While initially seeming massive when working with small local files, this size becomes relevant when storing files of hundreds of gigabytes.
The block size is configurable on a per-client basis.
Tradeoffs
Block size selection determines the number of chunks and corresponding I/O operations for reading and writing.
Larger blocks:
- Fewer blocks created
- Fewer I/O operations needed
- Increased memory requirements during processing
Smaller blocks:
- More blocks created
- More I/O operations required
- Lower memory consumption per block
- Benefits for small files and random access patterns
- Increases NameNode metadata overhead
- Creates scalability risks
The small files problem is a well-documented concern in distributed systems — too many small files create operational challenges.
Block size also impacts HDFS fault tolerance, though that falls outside this article’s scope.
Tuning for Efficiency
Reducing I/O through partition pruning provides substantial performance gains. Optimal block size selection yields strong results.
However, no universal solution exists. Selection depends on dataset characteristics, usage patterns, data type, use case, and additional factors.
High-level recommendations:
Files under a few hundred megabytes: Use smaller block sizes (64MB or 128MB) to minimize wasted block space.
Files several gigabytes or larger: Use larger block sizes (256MB or 512MB) to minimize generated blocks and unnecessary I/O.
These are just guidelines and selecting your optimal block size will likely require some testing on your side.